<parquet.version>1.8.1</parquet.version>
JDateTime 依赖 <jodd.version>3.3.8</jodd.version>
<dependency> <groupId>org.apache.parquet</groupId> <artifactId>parquet-hadoop</artifactId> <version>${parquet.version}</version> </dependency> <!-- jodd --> <dependency> <groupId>org.jodd</groupId> <artifactId>jodd</artifactId> <version>${jodd.version}</version> </dependency>package mapreduce.job.decodeparquet; import static org.apache.parquet.format.converter.ParquetMetadataConverter.NO_FILTER; import java.io.IOException; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.parquet.hadoop.ParquetFileReader; import org.apache.parquet.hadoop.metadata.ParquetMetadata; import org.apache.parquet.schema.MessageType; import org.apache.parquet.schema.Type; /** * 解析parquet文件 * @author 15257 * */ public class DecodeParquetApp { public static void main(String[] args) { Configuration conf = new Configuration(); String filePath = "D:\\BONC\\Shanxi\\data\\parquet\\002186_0.0"; try { ParquetMetadata parquetMetadata = ParquetFileReader.readFooter(conf, new Path(filePath), NO_FILTER); // 获取 parquet 格式文件的全部 schema MessageType schema = parquetMetadata.getFileMetaData().getSchema(); System.out.println(schema.toString()); List<Type> fields = schema.getFields(); for (Type field : fields) { System.out.println(field.getName()); } } catch (IllegalArgumentException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
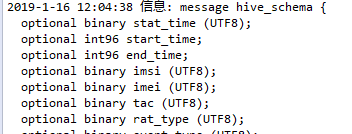
schema解释
message
固定声明,就像结构体中的struct一样。
hive_schema
message name,可以粗暴的理解为表名,因为里面都是field
optional,required,repeated
这是三种field的关键字,分别表示可选,必选,可重复选
可选和必选类似数据库中的nullable,可重复选是为了支持复杂的嵌套结构。
field类型
目前parquet支持int32,int64,int96(有些系统会把时间戳存成int96如老版hive),float,double,boolean,binary,fixed_len_byte_array。
参考类org.apache.parquet.schema.PrimitiveType.PrimitiveTypeName
UTF8
field的原始类型(Original Type),可以辅助field的type进行细粒度的类型判断。
参考类 org.apache.parquet.schema.OriginalType
group
嵌套结构声明,类似json对象
package test.parquet; import java.sql.Timestamp; import java.util.Calendar; import org.apache.hadoop.fs.Path; import org.apache.parquet.example.data.Group; import org.apache.parquet.example.data.simple.NanoTime; import org.apache.parquet.hadoop.ParquetReader; import org.apache.parquet.hadoop.example.GroupReadSupport; import org.apache.parquet.io.api.Binary; import jodd.datetime.JDateTime; public class ParquetReadTest { public static final long NANOS_PER_SECOND = 1000000000; public static final long SECONDS_PER_MINUTE = 60; public static final long MINUTES_PER_HOUR = 60; public static void main(String[] args) throws Exception { parquetReader("D:\\BONC\\Shanxi\\data\\parquet\\002186_0.0"); } private static void parquetReader(String inPath) throws Exception { GroupReadSupport readSupport = new GroupReadSupport(); ParquetReader<Group> reader = ParquetReader.builder(readSupport, new Path(inPath)).build(); Group line = null; while ((line = reader.read()) != null) { System.out.println(getTimestamp(line.getInt96("start_time", 0))); return; } } public static long getTimestamp(Binary time) { NanoTime nanoTime = NanoTime.fromBinary(time); int julianDay = nanoTime.getJulianDay(); long timeOfDayNanos = nanoTime.getTimeOfDayNanos(); JDateTime jDateTime = new JDateTime((double) julianDay); Calendar calendar = Calendar.getInstance(); calendar.set(Calendar.YEAR, jDateTime.getYear()); // java calender index starting at 1. calendar.set(Calendar.MONTH, jDateTime.getMonth() - 1); calendar.set(Calendar.DAY_OF_MONTH, jDateTime.getDay()); long remainder = timeOfDayNanos; int hour = (int) (remainder / (NANOS_PER_SECOND * SECONDS_PER_MINUTE * MINUTES_PER_HOUR)); remainder = remainder % (NANOS_PER_SECOND * SECONDS_PER_MINUTE * MINUTES_PER_HOUR); int minutes = (int) (remainder / (NANOS_PER_SECOND * SECONDS_PER_MINUTE)); remainder = remainder % (NANOS_PER_SECOND * SECONDS_PER_MINUTE); int seconds = (int) (remainder / (NANOS_PER_SECOND)); long nanos = remainder % NANOS_PER_SECOND; calendar.set(Calendar.HOUR_OF_DAY, hour); calendar.set(Calendar.MINUTE, minutes); calendar.set(Calendar.SECOND, seconds); Timestamp ts = new Timestamp(calendar.getTimeInMillis()); ts.setNanos((int) nanos); return ts.getTime(); } }解析结果
Binary{12 constant bytes, [-128, 81, 50, 42, -100, 13, 0, 0, -125, -125, 37, 0]}
NanoTime{julianDay=2458499, timeOfDayNanos=14964374000000}
2019-01-15 04:09:24.374
1547496564374
package com.bonc.AiMrLocate.job.parquetTest; import java.io.IOException; import java.util.Iterator; import org.apache.commons.lang.ArrayUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.parquet.example.data.Group; import org.apache.parquet.hadoop.ParquetInputFormat; import org.apache.parquet.hadoop.api.DelegatingReadSupport; import org.apache.parquet.hadoop.api.InitContext; import org.apache.parquet.hadoop.api.ReadSupport; import org.apache.parquet.hadoop.example.GroupReadSupport; import org.apache.parquet.io.api.Binary; import com.bonc.AiMrLocate.util.DateUtils; public class ParquetRunner { public static class WordCountMap extends Mapper<Void, Group, LongWritable, Text> { protected void map(Void key, Group value, Mapper<Void, Group, LongWritable, Text>.Context context) throws IOException, InterruptedException { try { Binary start_time = value.getInt96("start_time", 0); long timestamp = DateUtils.getTimestamp(start_time); String imsi = value.getString("imsi",0); String mme_group_id = value.getString("mme_group_id",0); String mme_code = value.getString("mme_code",0); String ue_s1ap_id = value.getString("ue_s1ap_id",0); String src_eci = value.getString("src_eci",0); context.write(new LongWritable(1),new Text(timestamp+","+imsi+","+mme_group_id+","+mme_code+","+ue_s1ap_id+","+src_eci)); } catch (Exception e) { return; } } } public static class WordCountReduce extends Reducer<LongWritable, Text, LongWritable, Text> { public void reduce(LongWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException { Iterator<Text> iterator = values.iterator(); while(iterator.hasNext()){ context.write(key,iterator.next()); } } } public static final class MyReadSupport extends DelegatingReadSupport<Group> { public MyReadSupport() { super(new GroupReadSupport()); } @Override public org.apache.parquet.hadoop.api.ReadSupport.ReadContext init(InitContext context) { return super.init(context); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String readSchema = ""; conf.set(ReadSupport.PARQUET_READ_SCHEMA, readSchema); Job job = new Job(conf); job.setJarByClass(ParquetRunner.class); job.setJobName("parquet"); String in = "D:\\Work\\MR定位\\山西\\数据字段说明及样例数据\\信令\\mme\\002186_0"; String out = "D:\\Work\\MR定位\\山西\\数据字段说明及样例数据\\信令\\mme\\output"; job.setMapperClass(WordCountMap.class); job.setInputFormatClass(ParquetInputFormat.class); ParquetInputFormat.setReadSupportClass(job, MyReadSupport.class); ParquetInputFormat.addInputPath(job, new Path(in)); job.setReducerClass(WordCountReduce.class); job.setOutputFormatClass(TextOutputFormat.class); FileOutputFormat.setOutputPath(job, new Path(out)); //判断output文件夹是否存在,如果存在则删除 Path path = new Path(out); //根据path找到这个文件 FileSystem fileSystem = path.getFileSystem(conf); if (fileSystem.exists(path)) { fileSystem.delete(path, true); System.out.println(out+"已存在,删除"); } job.waitForCompletion(true); } }